(文/陈济深编辑/张广凯)
"Soon,weseeyou."
4月28日上午,DeepSeek多模态团队研究员陈小康(X账号@PKUCXK)发出了这条推文。配图是两只蓝色的小鲸鱼——左边那只戴着画有"XX"的黑色眼罩,右边那只没戴眼罩、正常露出眼睛。
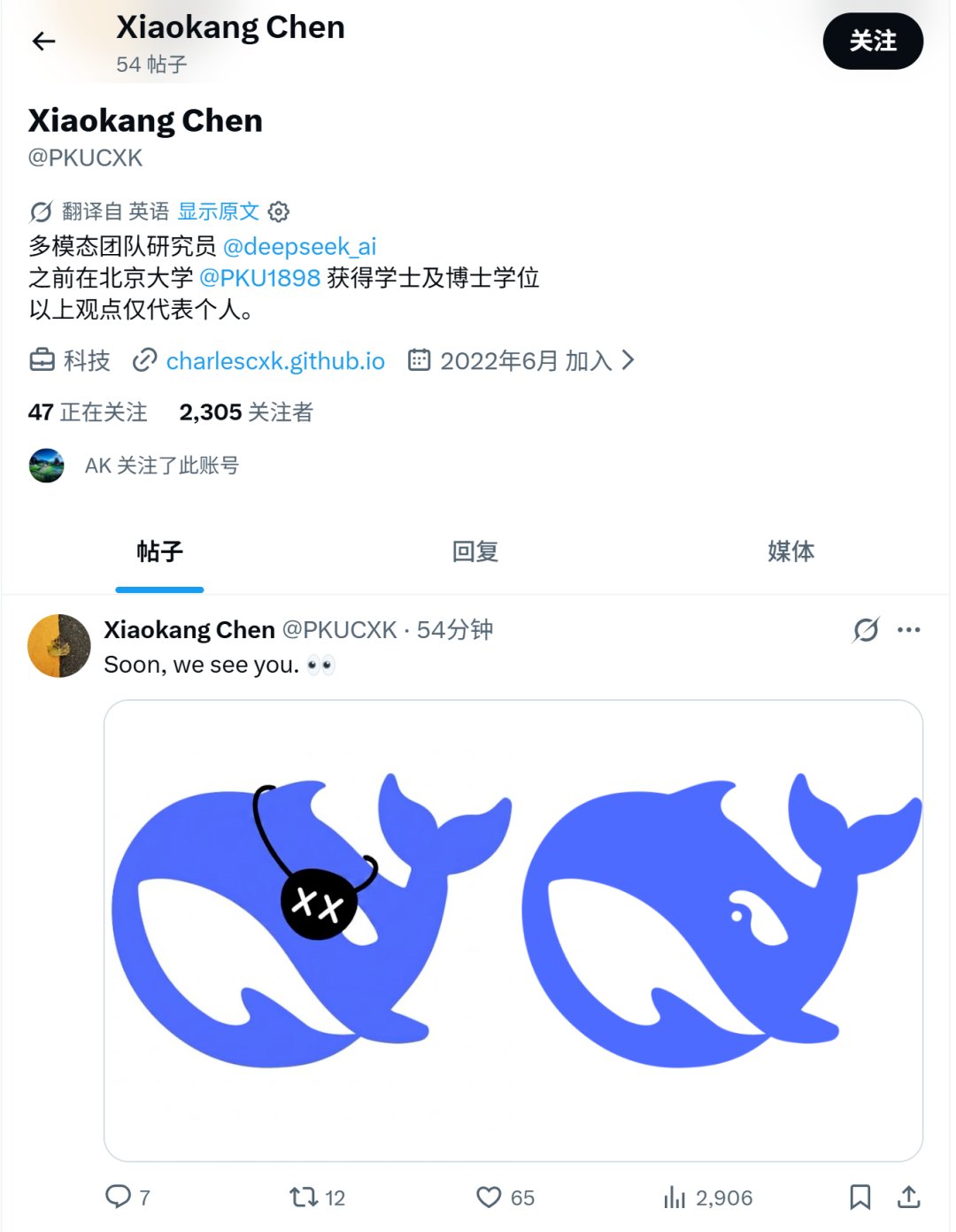
陈小康(@PKUCXK)4月28日发布的推文,配图为两只鲸鱼对照
尽管这条推文很快被陈小康自己删除了。但这条推文或在暗示DeepSeek的多模态功能或将近期上线。
除了该推文外,有用户截图显示,chat.deepseek.com输入框上方曾经出现过三个并列的标签——除了原有的「快速模式」「专家模式」,多出了一个「识图模式」,鼠标悬停后弹出的提示语是"图片理解功能内测中"。这是DeepSeek出圈以来第一次在主线产品里把视觉理解作为独立模式呈现。但需要说明的是,这个标签并不是所有用户都能看到,目前也无法确认它是常态化的灰度内测,还是短暂开放后又被回收——DeepSeek官方至此没有任何对外说明。
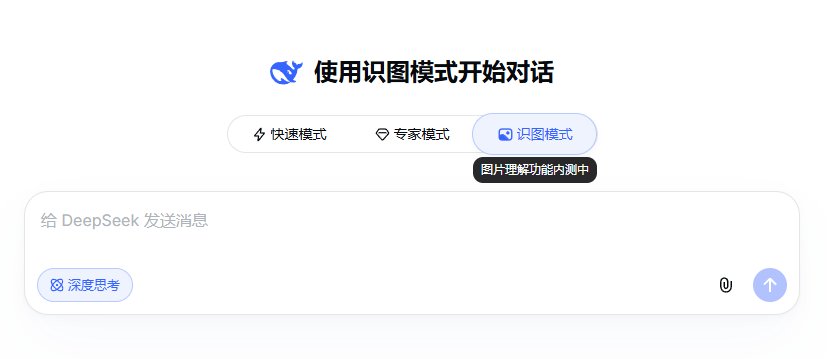
DeepSeek网页端出现的"识图模式"tab,标注"图片理解功能内测中"
根据该用户测试信息显示,在试图模式里,用户上传了一张人物照片并提问"这是什么动作姿势"。DeepSeek思考8秒后,先按位置、手臂、头部、头发、着装、光影逐项拆解了画面——"躯干呈一定角度,但面部明显朝向镜头""发丝散落在脸上和肩膀周围""高对比度,肤色苍白,深色衣服和阴影"——再给出最终判断:这是摄影和社交媒体语境里的"慵懒风躺姿"或"清冷氛围感姿势",常出现在小红书、抖音的"宅家""慵懒风""清冷感"等标签下。
值得记下的是这段思考过程里有一步明确的"自我修正考虑"。模型先列出了其他可能的解读——"手放在胸/肩处的『淑女』姿势"、"忧郁的自拍姿势"——再判断"慵懒氛围感姿势"才是最能涵盖所有细节的描述,最后才输出。这种结构化拆解、自我复核加文化语境识别的组合,已经超出DeepSeek过去主线产品上"图片识文字"的能力层次。

图3:沃垠AI流出的DeepSeek识图功能对话截图,显示了完整的拆解和自我修正过程
对话链接:https://chat.deepseek.com/share/ablc57vmv2ompm3vy6
值得注意的是,V2EX网友MichaelBitzo4月29日下午发帖称DeepSeekAPI已经返回"识图模式"字段,跟帖的其他用户实测反馈"还是不可用状态"——意味着接口侧的字段已经存在,但调用尚未对外开放。
DeepSeek-V4预览版4月24日上线,陈小康那条推文发布于4月28日,距离V4只隔了四天。多模态团队负责人发出预告,主线产品冒出新tab,对话分享链接生效,API字段返回——指向都比较一致:DeepSeek正在为主线产品装上视觉理解能力。但具体什么时候正式开闸、是否还会在五一假期前后落地,截至发稿尚没有官方时间表。
V4本身没有原生多模态。4月24日发布当天,DeepSeek官方对V4的定义集中在三件事上——百万级长上下文、Agent能力、推理性能。媒体复盘的判断也大致一致:V4在长上下文成本、Coding和Agent任务上达到了开源模型的第一梯队,但缺乏原生多模态是明显的短板。钛媒体的实测稿直言"V4目前并没有原生多模态功能,这会限制它在一些场景的发挥"。36氪的复盘稿则透露,DeepSeek暂缓多模态生成的训练策略,主要源于算力和现金的掣肘。
但DeepSeek的研究侧,并没有在多模态上停下来。
陈小康博士毕业于北京大学,2024年加入DeepSeek,主导多模态预训练和后训练工作。从他的Google学术页里能数出一长串相关成果——2024年12月开源的DeepSeek-VL2(基于MoE架构,激活参数最大4.5B)、2025年发布并被CVPR收录的Janus和JanusFlow,再到春节前后开源的Janus-Pro。其中Janus-Pro在GenEval图像生成基准上超过了DALLE-3和StableDiffusion3,是当时开源多模态阵营里最受关注的成果之一。
也就是说,DeepSeek多模态团队的论文和开源模型一直在出,缺的只是把这套能力接到主线产品上。
V4之前,DeepSeek主线产品里和"看图"有关的功能只有一项:chat.deepseek.com的"快速模式"支持识别图片中的文字,但本质是OCR调用,不是真正意义上的视觉理解。这一次冒出来的"识图模式",从沃垠那段对话case看,已经超出文字识别的层次,进入到画面语义、空间结构、氛围审美和文化语境的判断这一层。
事实上,铺垫4月初就开始了。4月8日,DeepSeek网页端在输入框上方第一次新增了「快速模式」和「专家模式」两个图标——这是DeepSeek出圈以来第一次在产品界面里做能力分层。爱范儿当时的实测稿援引技术KOLTeortaxes的判断:把Vision单独列为一个类是很不寻常的设计,DeepSeek此前拒绝在网页端部署DS-VL系列,原因是"尚未成熟"。如果Vision模式真的上线,背后支撑它的很可能已经是一个完全功能化的VLM,甚至是Janus系列的下一步演化。
也就是说,从4月8日的分层入口,到4月24日V4纯文本发布,再到4月28日陈小康那条已被删除的预告,到4月29日"识图模式"在网页端、对话分享和API三个层面同时冒头——这是一条连续的产品节奏,只是DeepSeek自己暂时还没把它说出来。
DeepSeek多模态团队近年也并非没有人员变动。据《京报网》援引的公开消息,DeepSeek多模态核心贡献者阮翀今年4月加盟自动驾驶公司元戎启行任首席科学家,DeepSeek-OCR系列核心作者魏浩然也在春节前后离职。在这些变动之后,多模态团队的产品化进度依然推进到当前节点,本身也是一个值得记录的信息。
DeepSeek把识图能力送上主线产品的时间点,落在一个比较特殊的行业拐点上。
按目前公开信息盘点,国内主要模型公司的多模态布局已经基本铺齐。阿里巴巴的Qwen系列推出了多代Qwen-VL视觉语言模型;智谱的GLM-V贯穿GLM-4和GLM-5两代;字节跳动和阶跃星辰把"全模态"作为核心定位,阶跃年初的Step3.5Flash把全模态能力首次开源;月之暗面的Kimi同步在视觉理解和Coding两条线并行;MiniMax在保持语言模型能力的同时把视频生成模型作为差异化优势。腾讯混元4月23日发布的Hy3preview则把对标目标定为DeepSeek和阿里。换句话说,国内头部模型公司里,主线产品上没有视觉理解能力的,目前只剩DeepSeek一家。
DeepSeek这次一旦正式开闸,意味着这条尾巴也合上了。中国头部模型公司全员"睁眼",这是2026年模型层一个比较结构性的变化。
让这件事变得更紧迫的是Agent。
V4发布稿里,DeepSeek官方明确提到针对ClaudeCode、OpenClaw、OpenCode、CodeBuddy等主流Agent产品做了适配优化,Agent能力是V4三个核心卖点之一。但纯文本Agent的能力上限是有限的——当Agent需要操作浏览器、读截图、看仪表盘、识别UI元素、处理图表和PDF的时候,没有视觉理解就没办法完成闭环。这也是过去半年ComputerUse、屏幕操作Agent这一类产品集中冒出来的原因。
智谱的AutoClaw、阿里云的CodingPlan、Anthropic的ComputerUse,在底层逻辑上共享一个判断:Agent要真正进入生产力场景,视觉能力是基础设施而不是锦上添花。从这个角度看,DeepSeek这次给主线产品装上识图能力,更接近补一张入场券,而不是单纯补短板。
不过具体效果还得等正式开闸之后看。沃垠流出的那个case里,DeepSeek识图模型表现出了画面拆解、自我复核和文化语境识别的能力,但单点case不能替代系统性测评。和Qwen-VL、GLM-V、Step的多模态版本相比能拉开多少差距,能不能接住开源社区对DeepSeek一贯的"打榜"期待,目前都没有可对比的数据。
另一个待观察的悬念是开源策略。DeepSeek过去把所有大版本模型都做了开源——包括VL、VL2、Janus系列。如果这次的识图能力最终也走开源路线,开源多模态阵营会再增加一个旗舰玩家;如果走闭源或半开源路线,则意味着DeepSeek在多模态商业化路径上做了一次和过去不同的选择。考虑到DeepSeek正在以超过200亿美元估值寻求融资,路径选择的信号意义不会小。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 203304862@qq.com
本文链接:https://jinnalai.com/jiaodian/825816.html
