IT之家4月2日消息,美团昨天发布LongCat-AudioDiT音频生成模型,彻底抛弃梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音(TTS),号称“突破零样本TTS音色克隆上限”。

据介绍,业界主流TTS引擎长期受困于“多阶段”的复杂流程:先预测中间声学特征(如梅尔频谱),再依赖一个独立的神经声码器将特征“翻译”成最终波形。这种流程本质上是在两个不同空间里“传话”,必然会累积误差,导致最终合成的声音丢失了高保真、个性化的细节。
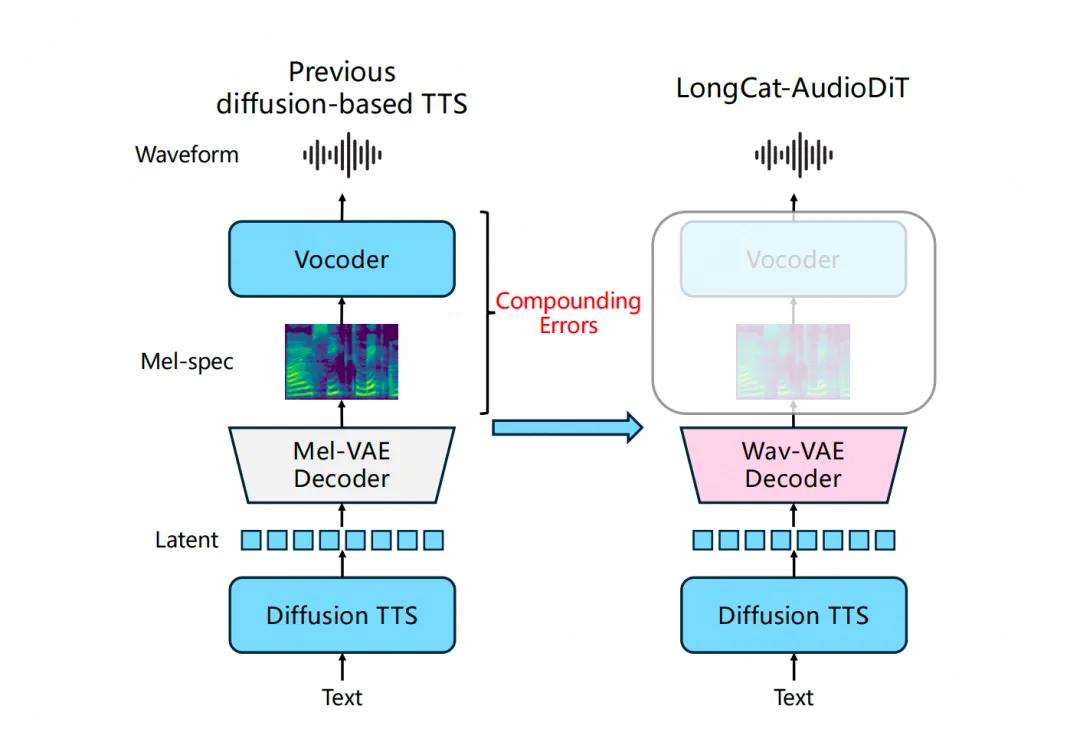
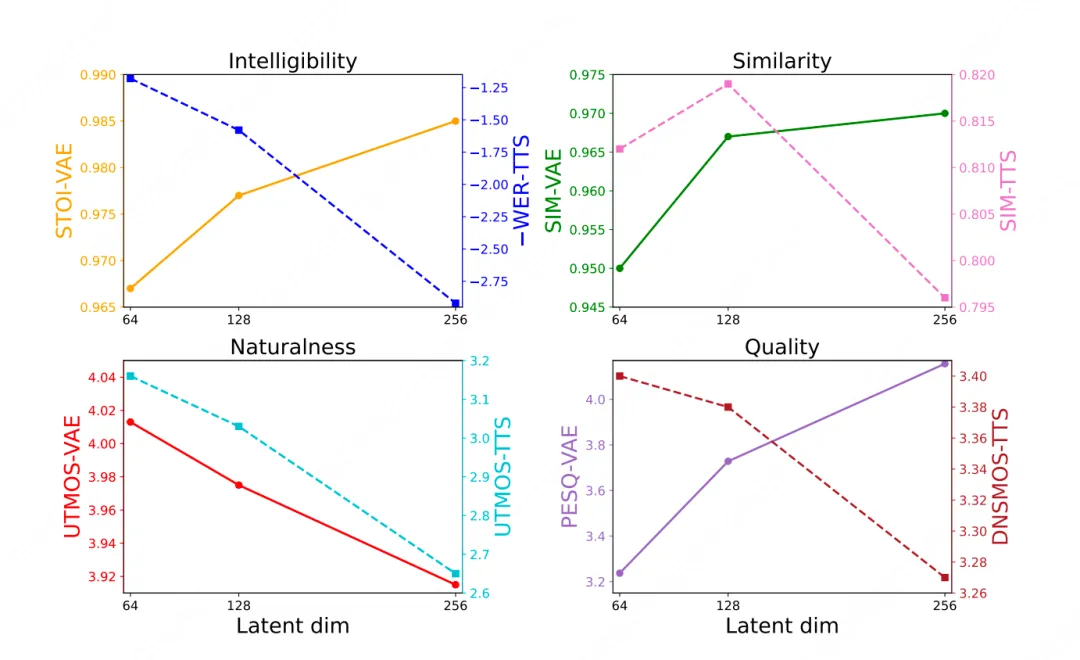
而LongCat-AudioDiT的核心架构逻辑非常简单,只用一个波形变分自编码器(Wav-VAE)和一个扩散Transformer(DiT),在波形隐空间里完成声音的压缩、建模与重建。拥有高效的下采样与多尺度建模、非参数捷径稳定训练以及对抗式多目标训练等多维度创新。
同时,该模型的骨干网络基于Transformer,集成全局自适应层归一化(GlobalAdaLN)、QK-Norm+RoPE稳定注意力训练等多项结构优化。还能够通过双重约束机制修复流匹配TTS的“训练-推理”不匹配问题。
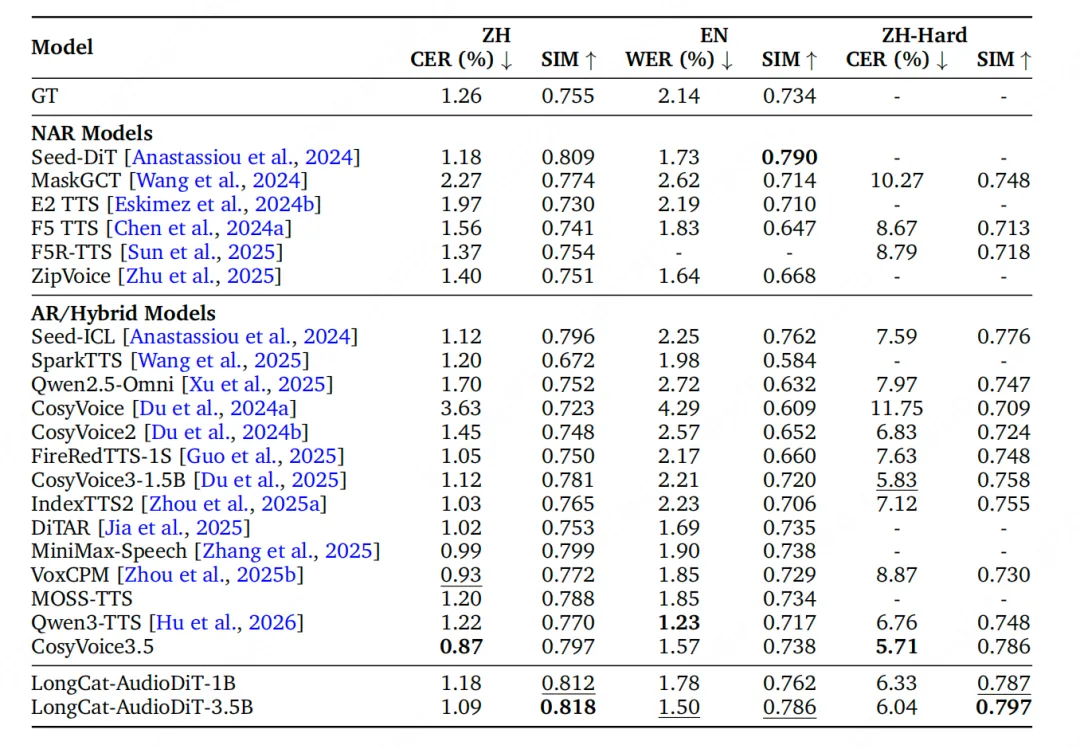
性能方面,该模型的3.5B版本在Seed-ZH测试集的说话人相似度(SIM)指标提升至0.818,Seed-Hard测试集达到0.797,超过了Seed-TTS、CosyVoice3.5、MiniMax-Speech等知名模型。
目前该模型已经开源,IT之家附1B/3.5B参数版本链接如下:
论文:https://arxiv.org/abs/2603.29339v1
GitHub:https://github.com/meituan-longcat/LongCat-AudioDiT
HuggingFace:https://huggingface.co/meituan-longcat/LongCat-AudioDiT
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 203304862@qq.com
本文链接:https://jinnalai.com/jiaodian/819579.html
