近期马斯克高调宣布推出Grok 3。这个被马老师称为“地球上最聪明的人工智能”是否名副其实呢?
从马斯克放出的测试图(数学、科学、代码)可以看出Grok3有四个版本:
分别是Grok-3、Grok-3 mini、Grok-Reasoning Beta和Grok-3 Reasoning mini。
其中Grok-3和Grok-3 mini是传统模型,Benchmark分别对标GPT-4o和DeepSeek V3
Grok-Reasoning Beta和Grok-3 Reasoning mini是最新的推理模型,benchmark分别对标OpenAI o1/o3和DeepSeek R1。
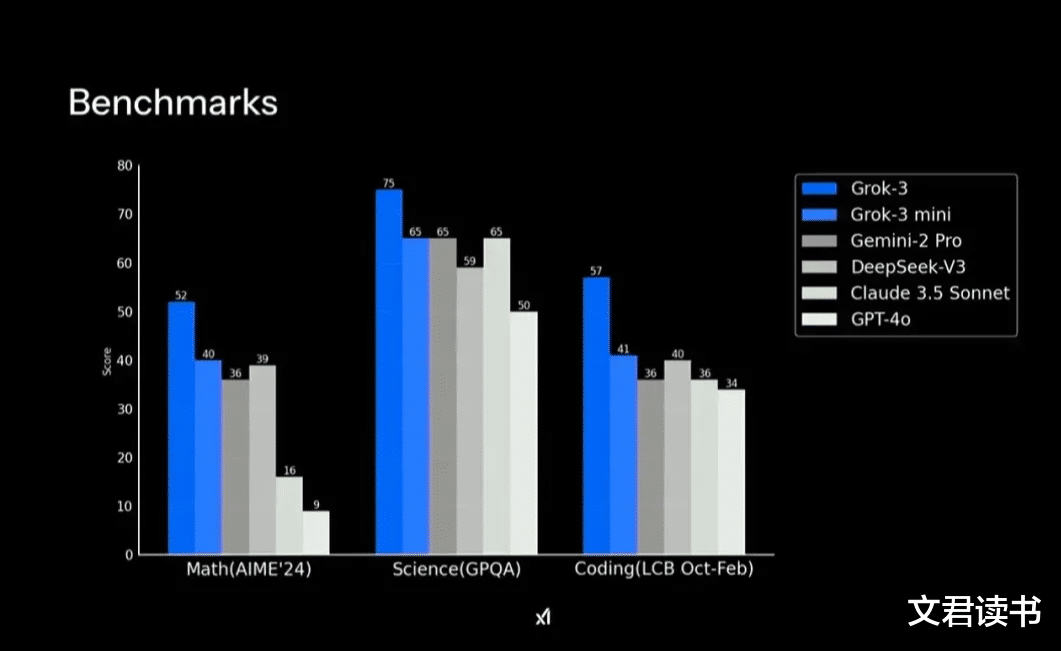
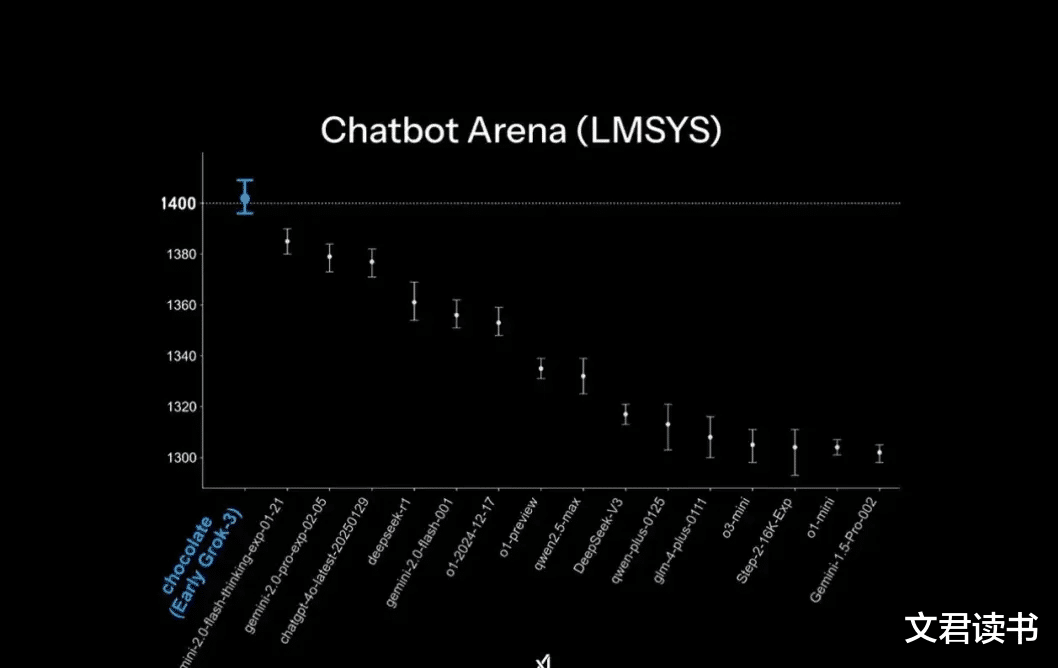
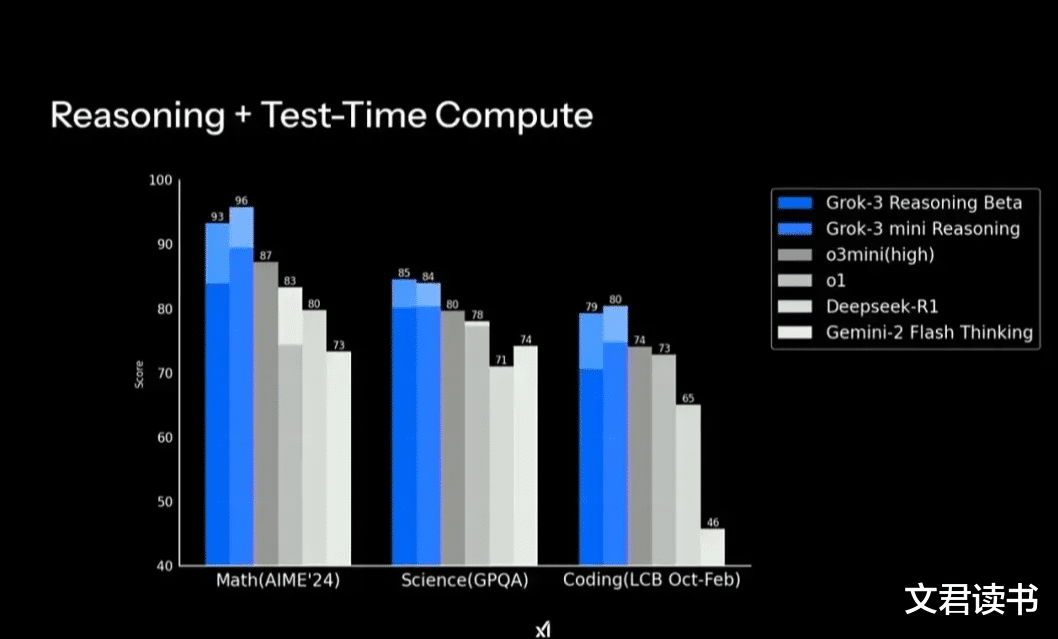
从基座测试结果来看,Grok-3的得分领先于DeepseekR1和Open AI的O1/O3mini,但差距并非很大。
马斯克这次可能是被迫应战,而且是xAI拿20万张GPU卡训出来的模型,除了基座测试分数之外,并无其他令人震撼的地方。
所以对比起Deepseek的训练成本,这款雄心勃勃的产品有点“起了个大早,赶了个晚集”的感觉。
Grok 3可以为Scaling Laws强行续命,但是从性价比上看:Scaling Laws的ROI(投资回报比)太低。
这还是因为DeepSeek的惊艳,货比货得扔。
马斯克财大气粗,也不意味着可以无限砸钱,而且Grok3的路子感觉被OpenAI给带偏了,都有一股“算力垄断”的金融资本意味在里面。

回顾一下xAI的大模型路径:
2023年11月,xAI发布第一款大模型Grok-1。
2024年3月18日,xAI团队发布参数量高达3140亿的Grok-1模型,这一参数量远超OpenAI GPT-3.5的1750亿,成为当时参数量最大的开源大语言模型。
2024年8月,Grok 2大模型发布 。
Grok 2主要应用于训练AI聊天机器人。
与Grok 1相比,Grok 2在训练数据的使用上有所改进。
Grok 1在训练时未完全依赖真实世界数据,采用了大量合成数据,导致在处理真实世界中的细微差别和复杂性时表现欠佳。
Grok 2融入了少量高质量的真实世界数据,一定程度上弥补了初代模型在处理真实场景方面的不足。
Grok 3,其最大的特点在于引入了“思维链”(Chain Of Thought)推理能力。该能力让Grok 3能够像人类认知过程一样逐步处理复杂任务,显著提高了模型处理复杂查询和提供更连贯、更有逻辑的响应的能力。
(眼熟不。DeepSeek R1已经具备这个能力。)
Grok 3模型在推理、编程能力以及文本和图像分析等多模态功能方面有了显著的提升。
2024年中,马斯克高调宣布:Grok-3将依托10万张英伟达H100 GPU的超强算力进行训练,计划在2024年底推出,并称赞其 “将会是非常特别的”。
但实际上,2024年底Grok-3并没有推出,业内的说法是xAI团队规模小资源少,因此进展缓慢。但2024年底规模、资源比他们小得多的DeepSeekR1惊艳一击,异军突起,让国内外震惊之余,很多大型企业已经纷纷接入DeepSeek。
我们国内就不说了,美国的一些巨头都是第一时间接入,这直接倒逼了OpenAI不情不愿的迅速开源和Grok 3的快速(相对于2024年的延期)发布。
如果Grok-3在DeepSeekR1之前发布,市场上或许还能抢占一块巨额蛋糕,但目前的情况下,DeepSeekR1如黑马崛起,逐鹿天下,而Grok-3在堆砌资源的情况下姗姗来迟,AI领域格局已经完全改变,曾经是一家独霸天下的OpenAI也不得不紧跟DeepSeek的开源步伐。
而后来的Grok-3并没有奇点突变,也没有令人惊艳的质变,仅凭着雄厚身家训练出基座测试领先(仅仅是领先而非代差)的产品,恐怕很难再改变市场格局。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 203304862@qq.com
本文链接:https://jinnalai.com/jiaodian/730981.html
