终于发布了!
4月24日,中国深度求索公司正式上线全新系列模型DeepSeek-V4预览版,并同步开源。该系列模型以百万字超长上下文为核心亮点,在Agent能力、世界知识和推理性能三大维度,均实现国内与开源领域的领先。
双版本同步更新满足不同场景
据悉,DeepSeek-V4系列包含两个MoE模型版本,分别是满足高性能研发的DeepSeek-V4-Pro(下称DS-V4-Pro),以及满足经济高效部署需求的DeepSeek-V4-Flash(下称DS-V4-Flash)。

其中,DS-V4-Pro总参数达1.6万亿,激活参数49B,主要面向尖端任务,性能比肩顶级闭源模型。DS-V4-Flash则总参数2840亿,激活参数13B,定位为经济之选。两款模型均原生支持1M上下文,且成为DeepSeek所有官方服务的标配。
根据官方公布的具体性能,DS-V4-Pro在Agent能力、世界知识和推理性能方面,达到了开源模型的前列。
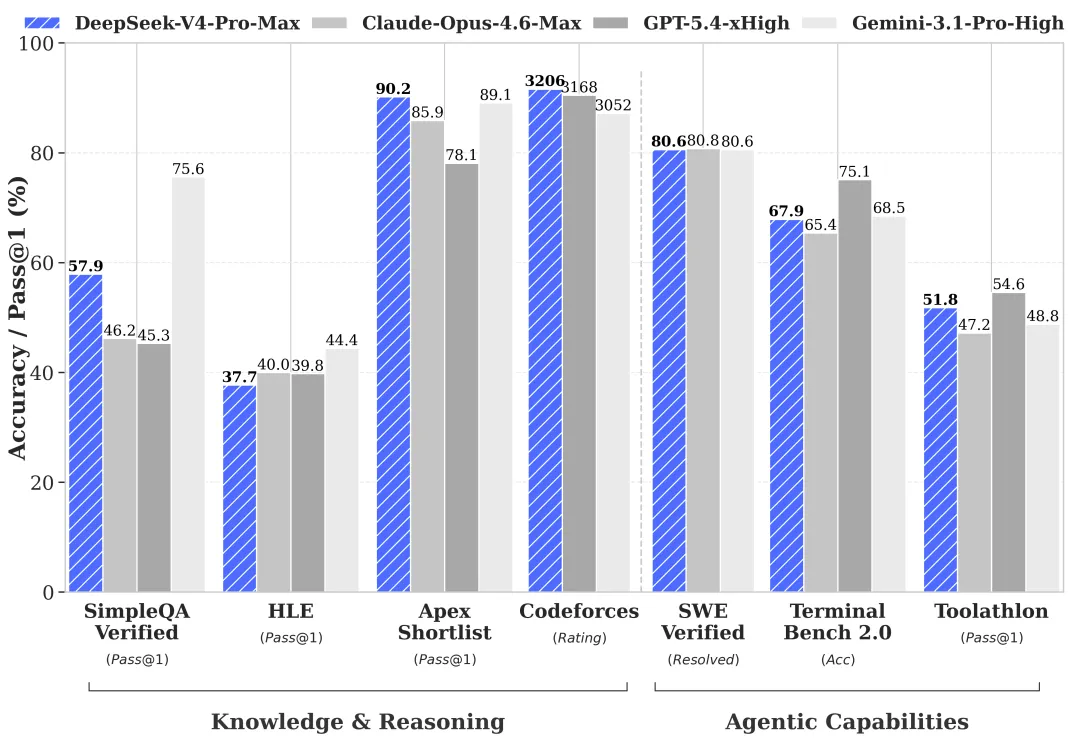
在AgenticCoding评测中,DS-V4-Pro版达到当前开源模型最佳水平,且已成为公司内部员工使用的AgenticCoding模型,使用体验优于Sonnet4.5,交付质量接近Opus4.6非思考模式。
世界知识测评中,DS-V4-Pro大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。
在数学、STEM、竞赛型代码等推理任务中,DS-V4-Pro超越所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
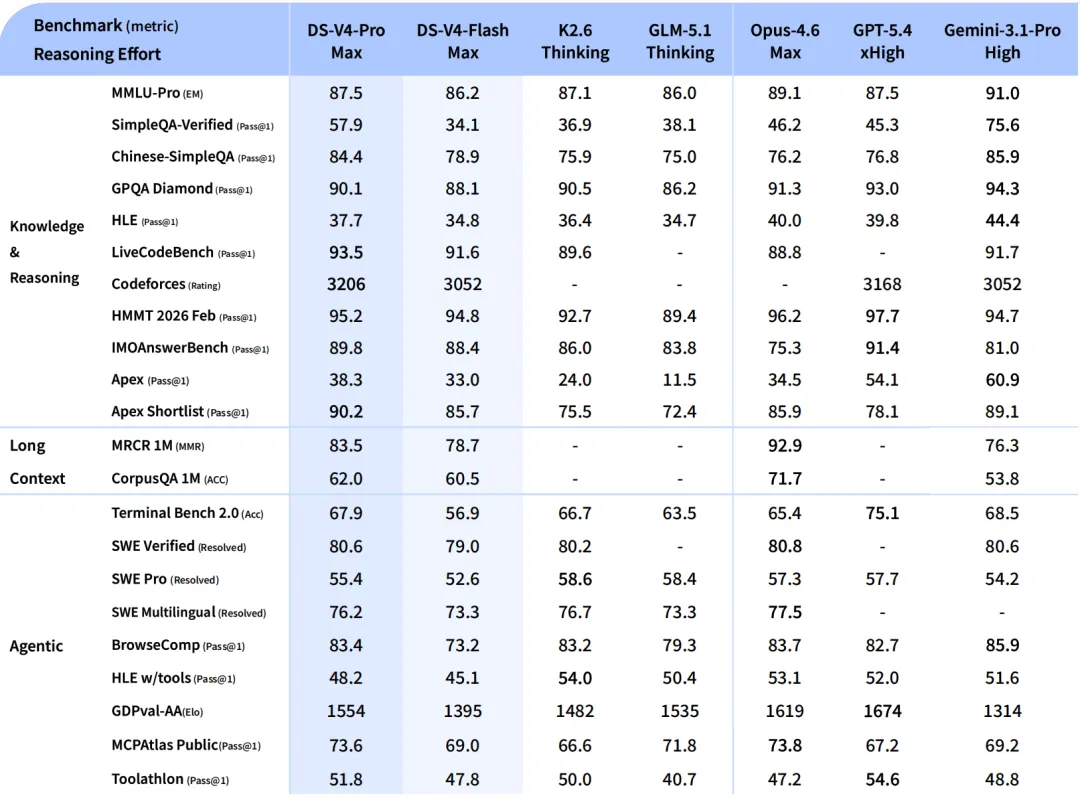
与DS-V4-Pro相比,DS-V4-Flash在世界知识储备方面稍逊一筹,但推理能力与其接近。由于模型参数和激活更小,DS-V4-Flash能够提供更加快捷、经济的API服务。在Agent评测中,Flash版在简单任务上与Pro版旗鼓相当,但在高难度任务上存在差距。
在性能、成本与开源生态间找到平衡点
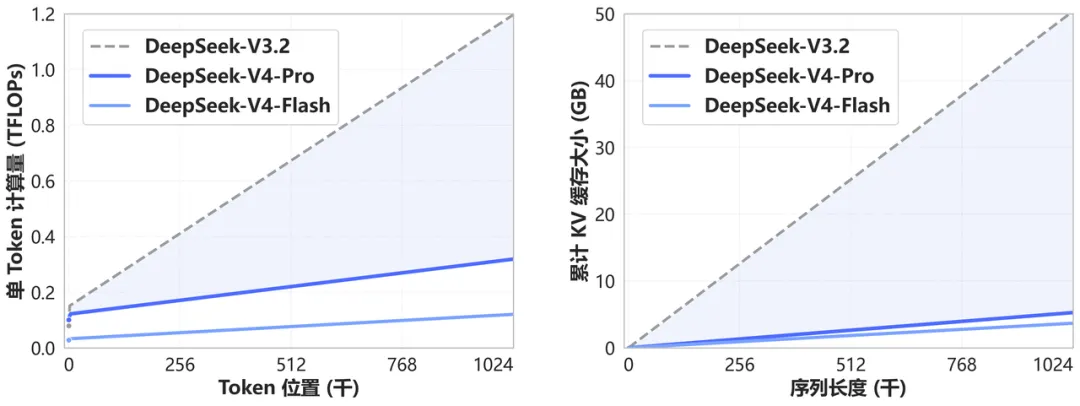
值得一提的是,DeepSeek-V4开创了一种全新的注意力机制,在token维度进行压缩,结合DSA稀疏注意力(DeepSeekSparseAttention),实现了全球领先的长上下文能力。相比传统方法,该技术大幅降低了对计算和显存的需求。如下图所示,相比DeepSeek-V3.2,所需的计算量和显存容量已大幅降低。
目前,DeepSeek-V4可通过官网及官方App直接使用。API服务也同步上线,支持OpenAIChatCompletions与Anthropic两套接口标准,开发者将model参数修改为deepseek-v4-pro或deepseek-v4-flash即可调用。
API定价方面,DeepSeek继续延续高性价比策略。以每百万tokens计:DS-V4-Flash输入(缓存命中)0.2元、输入(缓存未命中)1元、输出2元;DS-V4-Pro版则分别为1元、12元、24元。而官网聊天与App端仍保持免费。
此外,官方还特别提到,目前DS-V4-Pro服务吞吐有限,预计下半年华为昇腾950超节点批量上市后,Pro价格会大幅下跌。
不得不说,DeepSeek-V4在百万上下文、推理性能和成本控制上的全面突破,重新定义了开源模型的竞争力天花板。也再一次让世界看到了中国大模型团队,在基础设施层的深层思考和务实野心。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 203304862@qq.com
本文链接:https://jinnalai.com/jiaodian/824589.html
