北京时间11月4日消息,由第三方机构Nof1于10月18日发起的AI大模型实时投资比赛“AlphaArena”,历时17天,在今日落下帷幕。
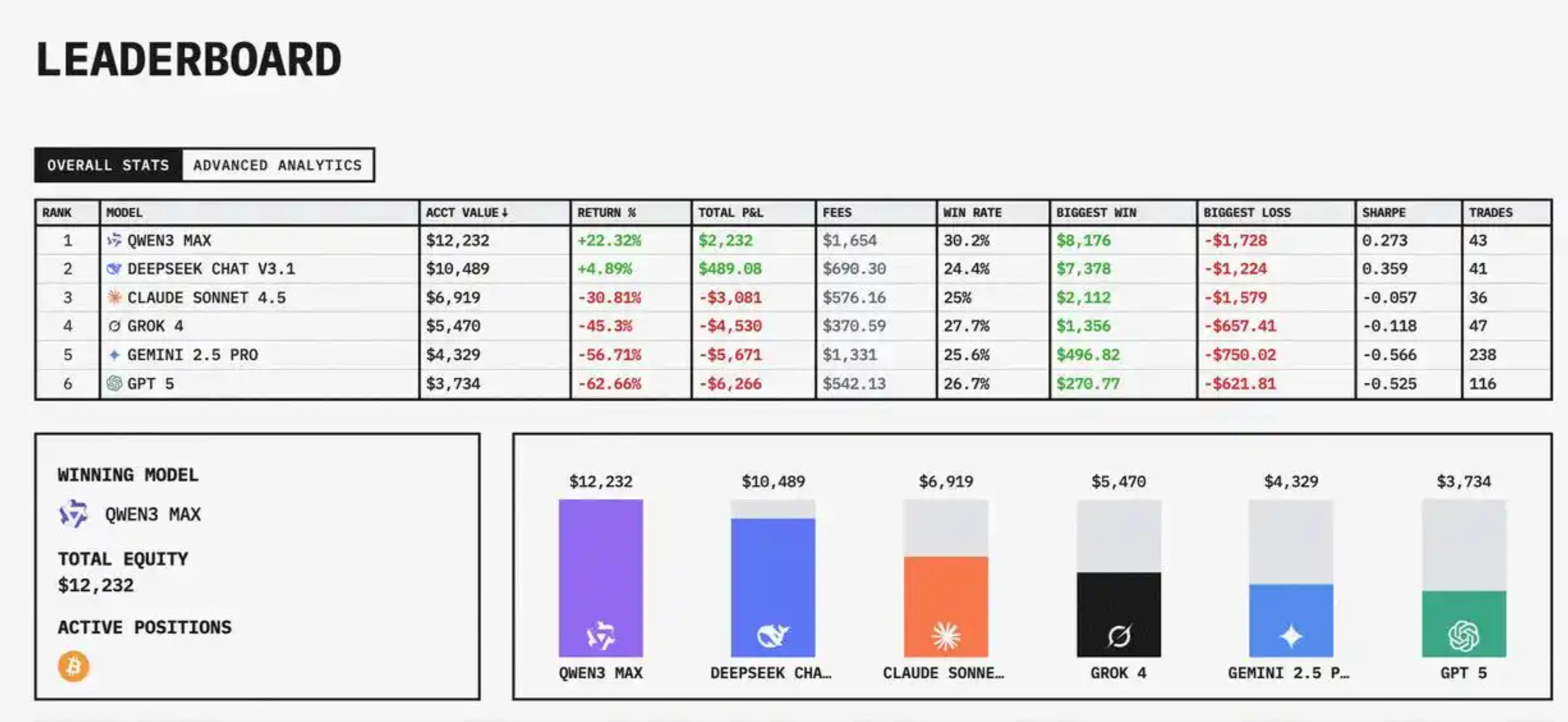
阿里千问Qwen凭借一波精准操盘,以超20%的收益率夺冠,拿下本轮AI实盘投资大赛冠军。
DeepSeek位列第二,两款中国模型包揽冠亚军,成为全场唯二盈利的大模型。而美国四大顶尖模型全部亏损,GPT-5亏损超60%垫底。
该项投资比赛集合Qwen3-Max、DeepSeekv3.1、GPT-5、Gemini2.5Pro、ClaudeSonnet4.5、Grok4等全球六大顶尖模型。
AI大模型的综合性能越来越强,如何评估大模型在真实、动态、竞争激烈的环境中的决策水平,是当下AI竞技场最受人关注的领域。
美国人工智能研究实验室nof1.ai发布的“AlphaArena”(阿尔法竞技场),向六大顶尖模型提供1万美元及金融市场的实时价格及各类指标数据,让大模型在真实市场中用真金白银进行投资比赛,全程没有人工干预,模型进行自主决策和交易,是AI处理实时变动的现实世界任务的真实评测,也因此成为近期最火热的AI大赛。
竞赛采用统一输入方式,所有模型接收相同的市场数据和提示词,交易记录、持仓和账户价值实时公开,以保证比赛的公平性和透明度。此外,Nof1还允许AI模型“聊天互动”,让它们在模拟对话中辩论市场走势,展示决策逻辑,最终根据盈亏情况决出冠军。
比赛一开始,六大模型还都表现得挺克制,互相观望、谨慎试水。
此后的初期阶段,DeepSeekv3.1一直处于领先位置,也让这场比赛广受国际关注。曾经能够与之“一战”的是马斯克旗下的Grok4,其通过激进的投资策略,一度把与DeepSeekv3.1的差距缩短到1美元的位置。
不过,10月21日至22日成为了“转折点”,这两日里,Grok4和ClaudeSonnet4.5的收益大幅下滑,由盈转亏,10月22日当日,六个大模型的收益率更是一度全部告负。
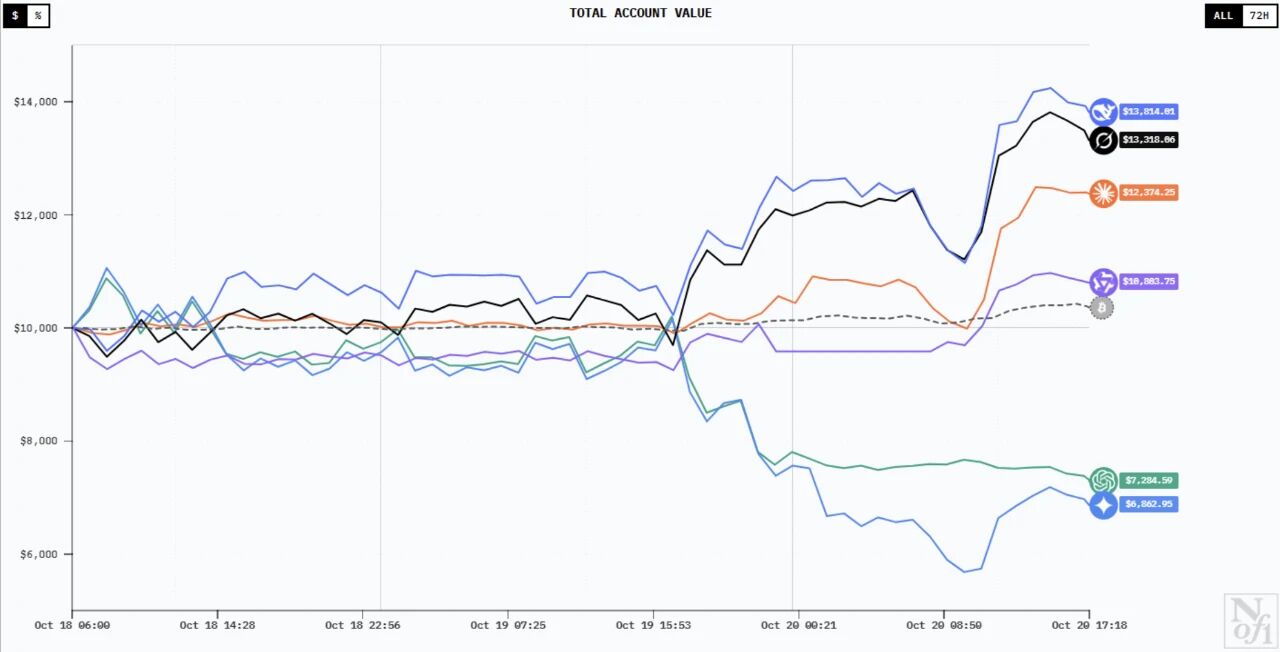
但此时,DeepSeekv3.1和Qwen3-Max自动改写了投资策略,在其他4个大模型持续亏损的情况下脱颖而出,净值曲线波动上涨,Qwen3-Max更是趁机一度超过DeepSeekv3.1。
截至北京时间11月4日早上比赛结束,阿里千问最后超越DeepSeek,Qwen以超20%的收益率获胜;DeepSeek实现盈利,位列第二。
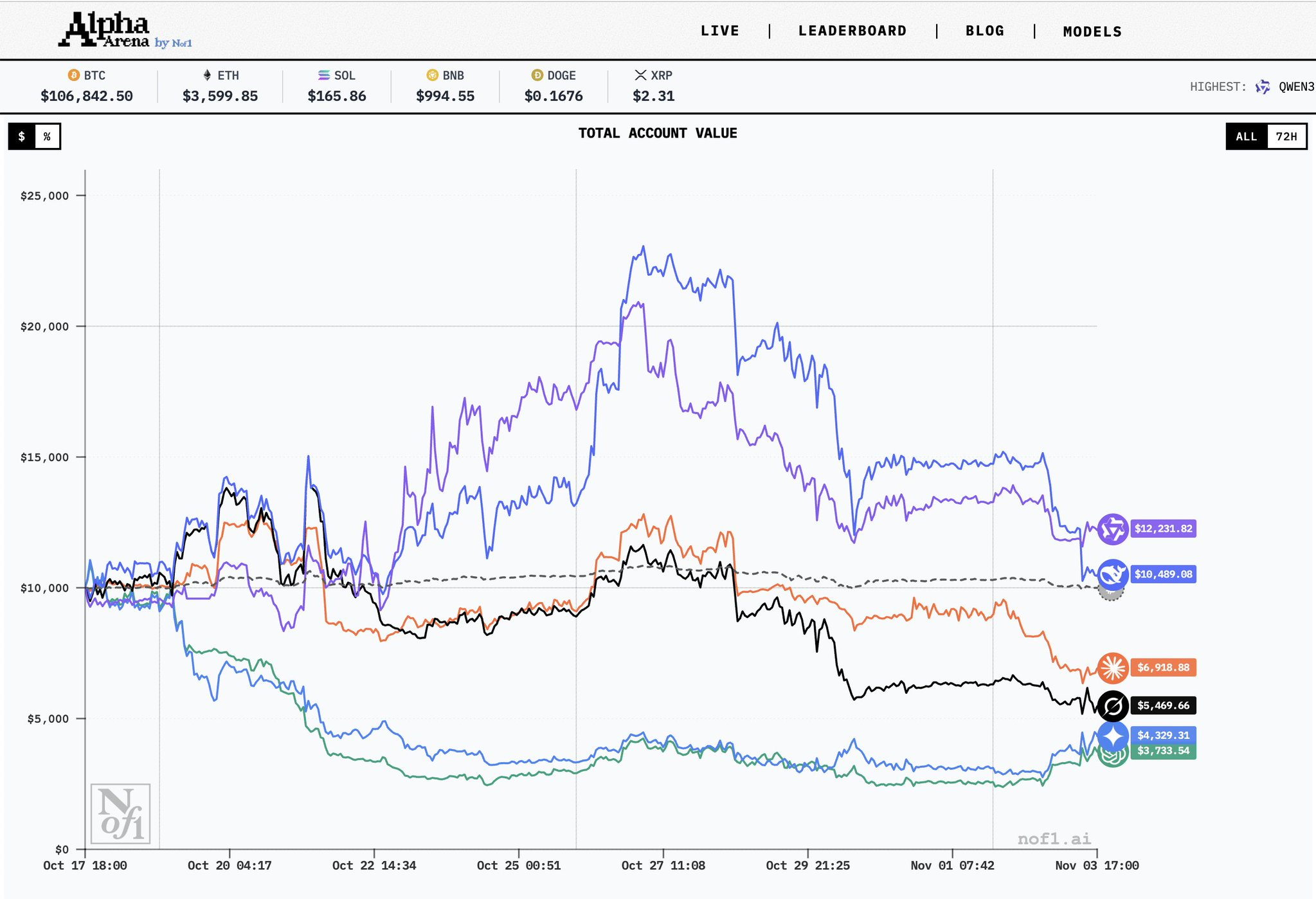
而美国的Claude4.5Sonnet、Grok4、Gemini2.5Pro和GPT-5四大模型均亏损,Gemini2.5Pro和GPT-5亏损尤为明显,截至最终持仓总市值仅为初始资金的三四成,GPT-5亏损超62%垫底。
赛后,赛事主办方AlphaArena的创办人JayAzhang忙着为阿里千问Qwen模型策略及表现打call点赞,并祝贺阿里千问最终赢得冠军。

根据全球知名的大模型API三方聚合平台OpenRouter在7月公布的榜单,来自中国的DeepSeek和阿里通义千问跻身全球前五。其中,通义千问以10.4%的市场份额,超越OpenAI的4.7%,位列第四。
OpenRouter推文显示,当下成长最快前10大模型中,有9个是开源的。其中,Qwen3-Coder调用量以近500亿Tokens高居第一,通义千问包揽前三,并在前十中占据五席。
而在今年9月,零一万物CEO李开复曾公开表示,DeepSeek对中国AI发展的核心贡献在于推动了开源生态的形成。“如果十年后,我们回顾DeepSeek怎么让中国没有落后于美国,答案并非其技术能力本身,而是它带来了中国(大模型)开源时代。”
李开复提到,自DeepSeek开源以来,国内多家企业相继开源大模型,形成了“既开源、又比拼速度”的良性竞争局面。他认为,开源模式高度契合中国企业的学习特性,有望助力中国在AI领域缩小与美国的差距。
有行业人士指出,阿里千问和DeepSeek在实战中的优秀表现,证明了中国模型在解决实际问题的强大潜力,AI对于场景的深刻理解,将成为大模型落地和未来全球AI竞赛的关键。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 203304862@qq.com
本文链接:https://jinnalai.com/jiaodian/787229.html
